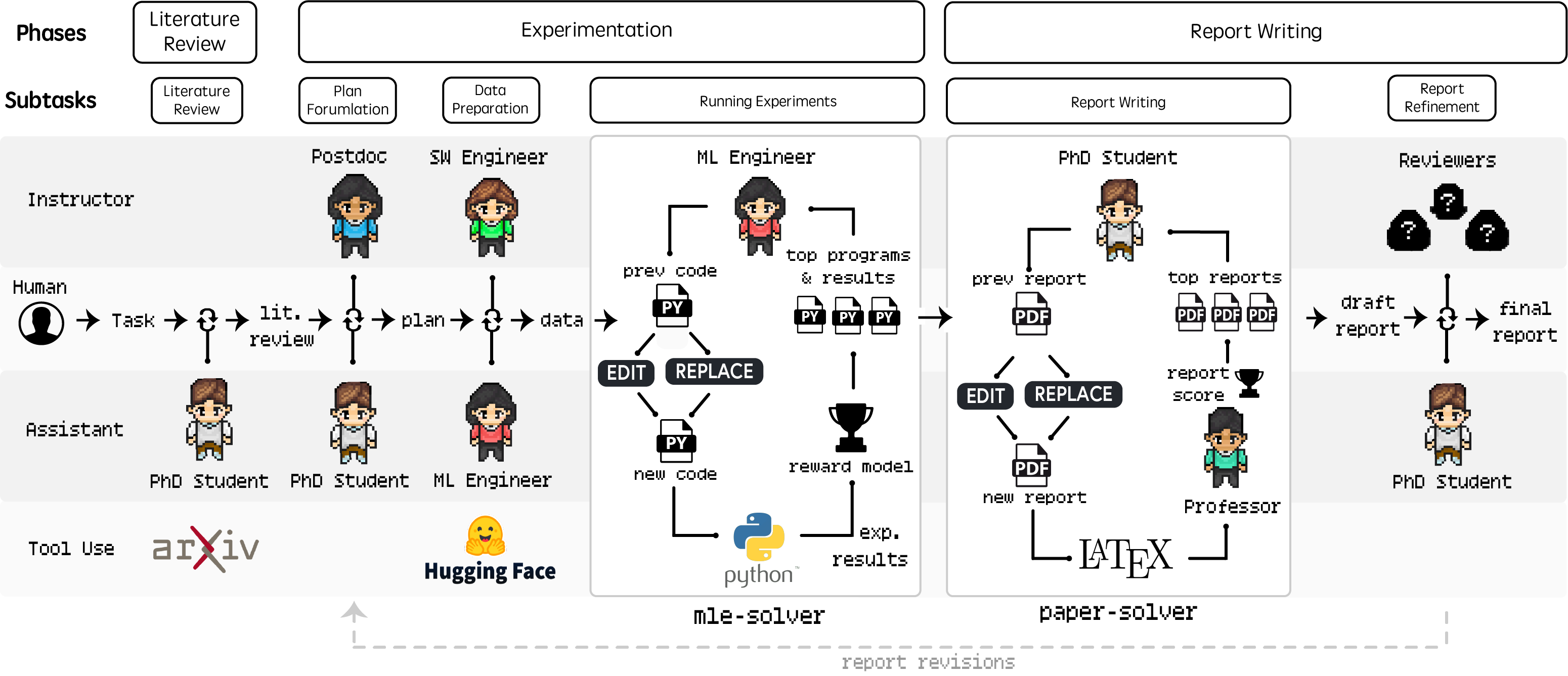
Agent Laboratory takes as input a human-produced research idea and outputs a research report and code repository. First and foremost, Agent Laboratory is meant to assist you as the human researcher toward implementing your research ideas. You are the pilot. Agent Laboratory provides a structured framework that adapts to your computational resources, whether you're running it on a MacBook or on a GPU cluster. Agent Laboratory consists of specialized agents driven by large language models to support you through the entire research workflow—from conducting literature reviews and formulating plans to executing experiments and writing comprehensive reports. This system is not designed to replace your creativity but to complement it, enabling you to focus on ideation and critical thinking while automating repetitive and time-intensive tasks like coding and documentation. By accommodating varying levels of computational resources and human involvement, Agent Laboratory aims to accelerate scientific discovery and optimize your research productivity.
Agent Laboratory consists of three primary phases that systematically guide the research process: (1) Literature Review, (2) Experimentation, and (3) Report Writing. During each phase, specialized agents driven by LLMs collaborate to accomplish distinct objectives, integrating external tools like arXiv, Hugging Face, Python, and LaTeX to optimize outcomes. This structured workflow begins with the independent collection and analysis of relevant research papers, progresses through collaborative planning and data preparation, and results in automated experimentation and comprehensive report generation. Details on specific agent roles and their contributions across these phases are discussed in the paper. The modular design ensures compute flexibility, accommodating diverse resource availability while maintaining efficiency in generating high-quality research artifacts.
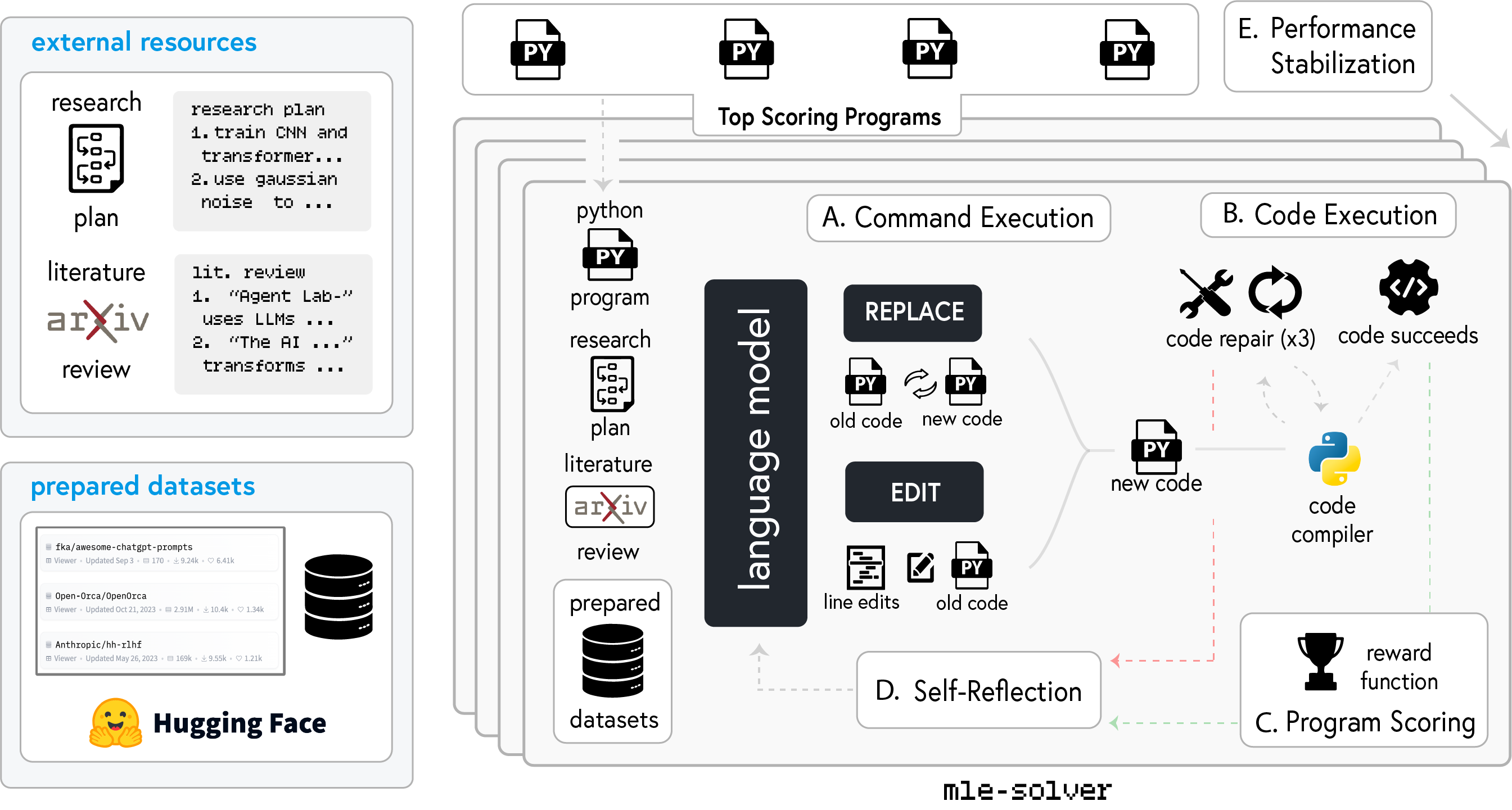
The first step toward performing research is building the capability for solving ML problems. Agent Laboratory addresses this through the mle-solver. This tool acts as a general purpose ML code solver, taking in research directions from previous phases as text and iteratively improving research code. To accomplish this, a collection of top programs are iteratively conditioned on inputs like task instructions, command descriptions, and distilled knowledge in order to improve the experimental results according to a scoring function. A set of changes are generated via two commands: REPLACE, which rewrites all code, and EDIT, which modifies specific lines. Successfully compiled code updates top programs based on scores, while errors prompt up to three repair attempts before trying new code. The agent reflects on each step to refine outcomes.
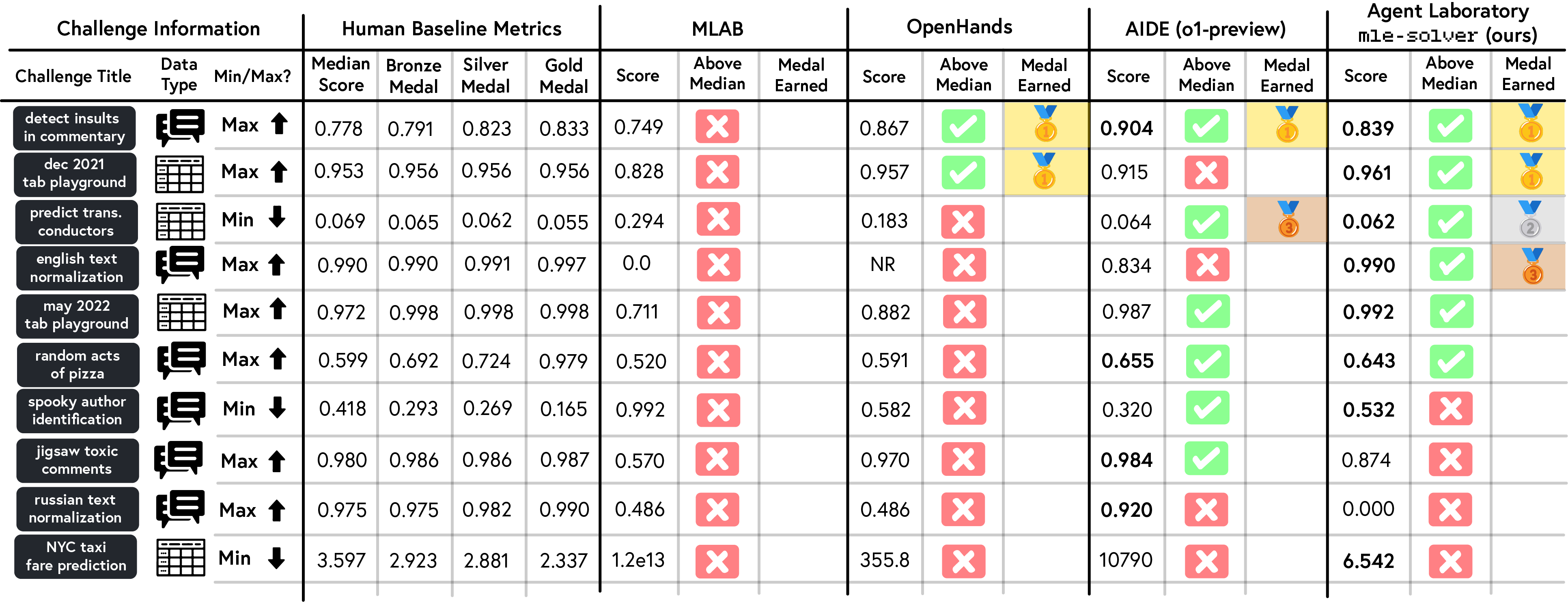
MLE-Bench Evaluation: In order to assess the effectiveness of mle-solver independent of the full Agent Laboratory workflow, we evaluate it in isolation on a subset of 10 ML challenges from MLE-bench. MLE-bench is a benchmark designed to assess the capability of agents in handling real-world ML tasks on Kaggle competitions. This benchmark compares agent performance with human baselines, scoring agents with Kaggle’s medal system, and incorporating mechanisms to mitigate contamination and plagiarism risks. We find that Agent Laboratory’s mle-solver is more consistently high scoring than other solvers, with mle-solver obtaining four medals (two gold, one silver, and one bronze) compared with OpenHands (gpt-4o) obtaining two medals (two gold), AIDE (o1-preview) obtaining two medals (one gold, one bronze) and MLAB obtaining zero medals. Additionally, mle-solver obtained above median human performance on six out of ten benchmarks, with AIDE obtaining five out of ten, OpenHands two out of ten, and MLAB zero out of ten.
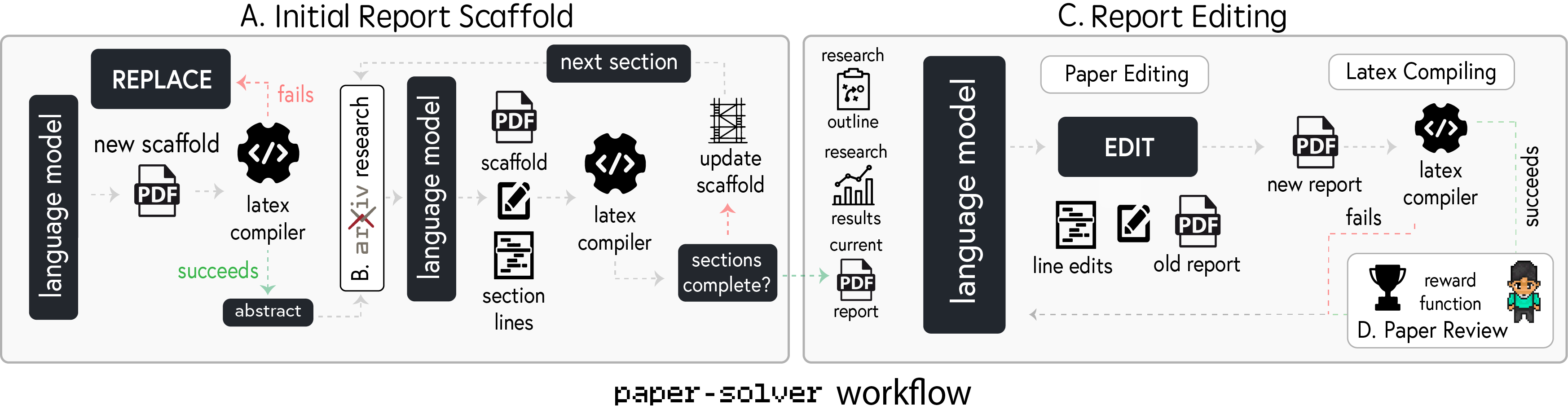
The second step is generating a research report based on the experiment design and results. For this we introduce the paper-solver, which focuses on report generation. This module acts as a results and code-to-report generator, summarizing the outputs and findings from previous experimental phases into a human-readable academic paper. paper-solver synthesizes research from previous stages, providing researchers with a clear summary of accomplishments. Inputs include the research plan, experimental results, derived insights, and a literature review, producing outputs in the standard academic paper format suitable for conference submissions.
This study evaluated the human-perceived quality of research outputs generated by three language model backends—gpt-4o, o1-mini, and o1-preview—along three dimensions: experimental quality, report quality, and perceived usefulness. Using five research questions as templates, 15 papers were autonomously generated by Agent Laboratory and subsequently reviewed by 10 volunteer PhD students. These reviewers assessed the outputs on a scale of 1 to 5. Results revealed that o1-preview delivered the highest perceived usefulness (4.4/5) and report quality (3.4/5), though its experimental quality was slightly lower (2.9/5). The o1-mini model achieved the highest experimental quality score (3.2/5), with consistent performance across the other two dimensions. In contrast, gpt-4o scored lowest overall, particularly in experimental quality (2.6/5), though it retained a relatively strong usefulness rating of 4.0/5. These findings indicate notable differences in how well each backend aligns with researcher expectations for autonomous research generation.
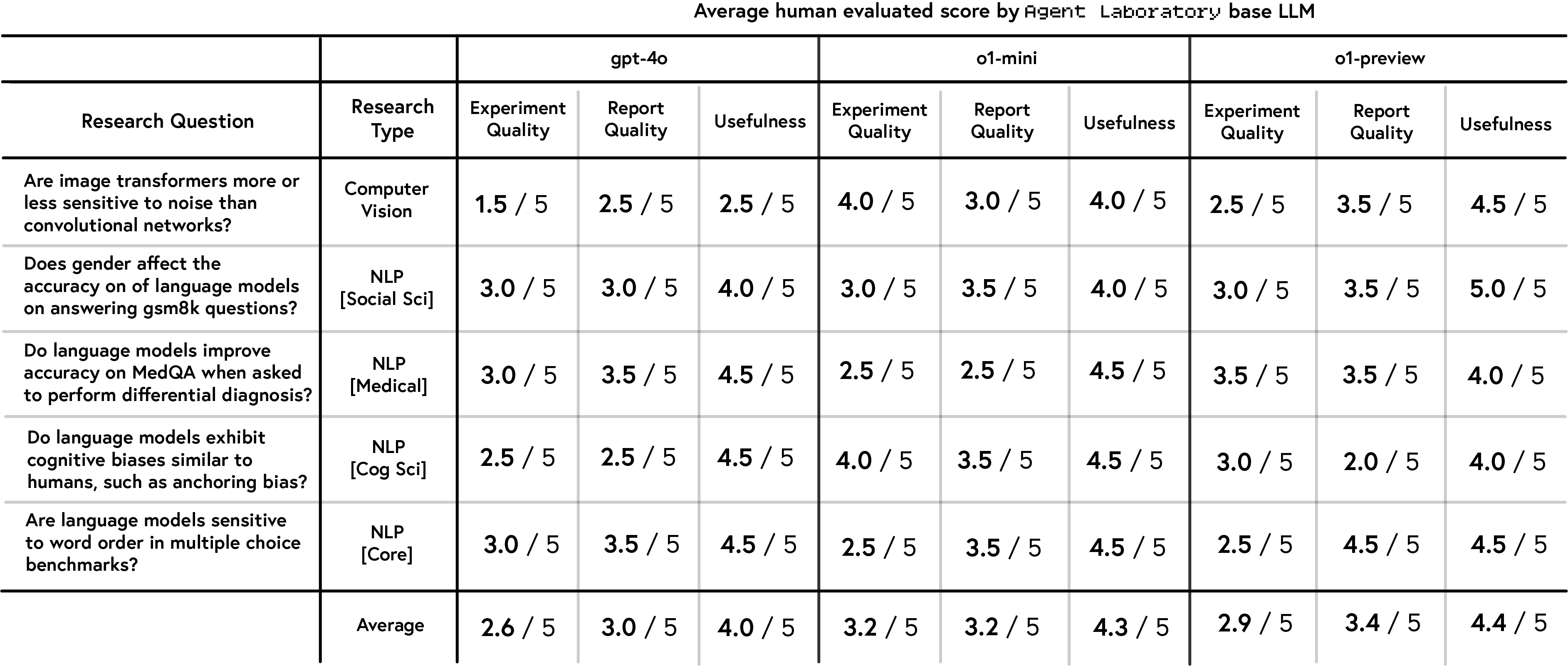
The analysis further revealed that the perceived quality varied based on research topics. For instance, the word order topic received the highest average report quality (3.8/5) and usefulness (4.5/5) but shared the lowest experimental quality rating (2.7/5) with the image noise topic. The cognitive bias topic achieved the highest experimental quality (3.2/5). Variability was particularly pronounced in the image noise topic, where gpt-4o scored poorly (1.5/5 for experimental quality and 2.5/5 for usefulness) while o1-mini excelled (4.0/5 and 4.5/5, respectively).
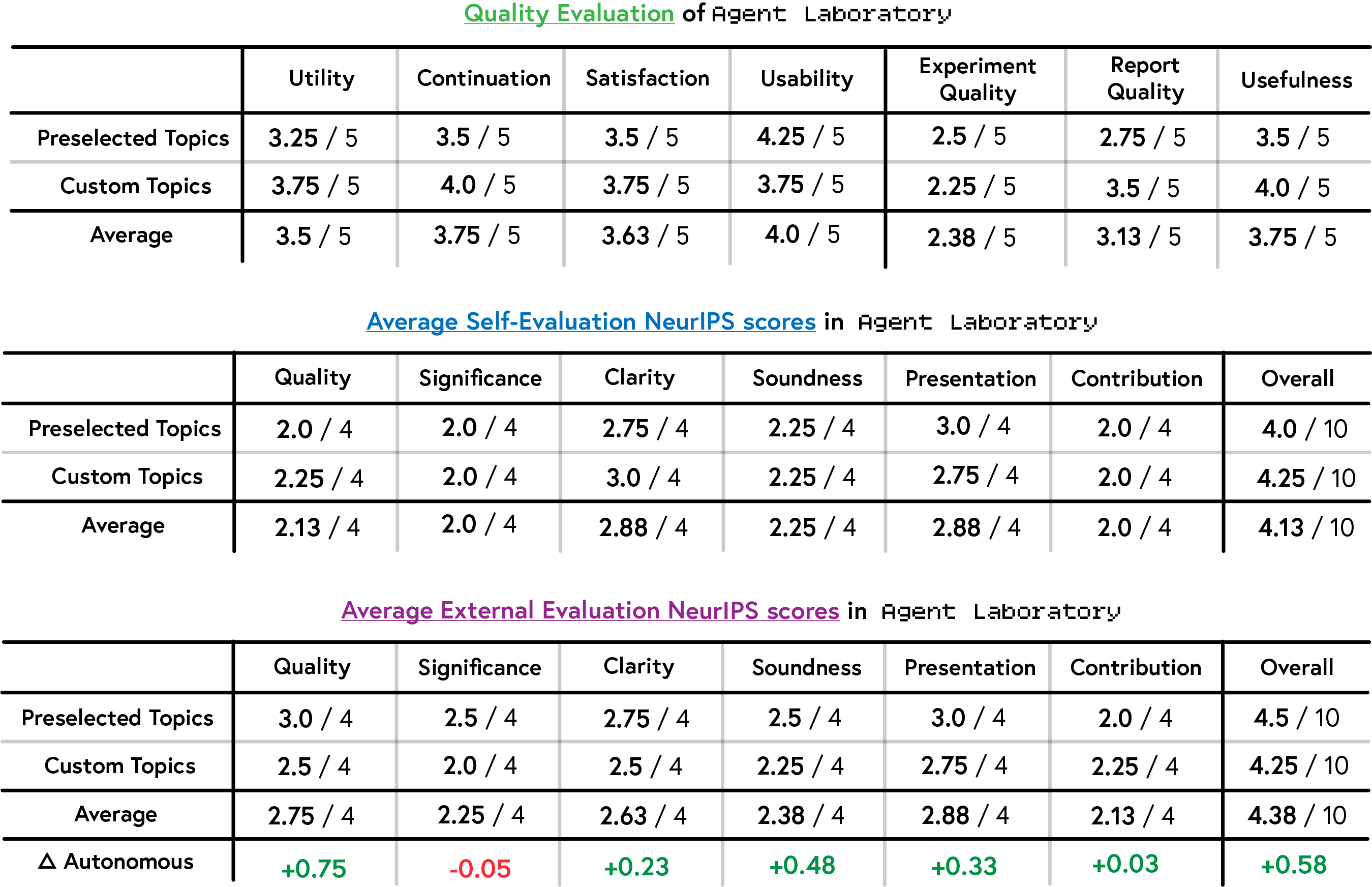
Human reviewers evaluated papers generated by Agent Laboratory using NeurIPS-style criteria, assessing quality, significance, clarity, soundness, presentation, and contribution. Across all metrics, o1-preview achieved the highest average overall score (4.0/10), followed by o1-mini (3.8/10) and gpt-4o (3.5/10). While o1-mini excelled in quality with a score of 2.3/4 and o1-preview led in soundness (2.2/4), all models showed modest performance in significance (2.2–2.5/4) and contribution (average 2.1/4), highlighting limited originality and impact. Clarity scores varied slightly, with gpt-4o rated highest (2.6/4). Despite these differences, all models fell well below the average score of 5.9 for accepted NeurIPS papers, indicating substantial gaps in technical and methodological rigor. These findings emphasize the need for further refinement of Agent Laboratory to align with the standards of high-quality research publications.

We next evaluate Agent Laboratory in co-pilot (human-guided) mode. Researchers rated the tool on utility, continuation likelihood, satisfaction, and usability, scoring it 3.5/5, 3.75/5, 3.63/5, and 4.0/5, respectively, across custom and preselected topics. Custom topics generally received higher scores, particularly in utility (+0.5), continuation (+0.5), and satisfaction (+0.25), though usability was rated marginally lower (-0.5). Preselected topics performed better in external evaluations, contrasting with the higher scores custom topics received in self-assessments. In assessing paper quality, co-pilot scores improved compared to the autonomous mode, with an average overall score increase from 3.8/10 to 4.38/10 (+0.58). Gains were observed in quality (+0.75), clarity (+0.23), soundness (+0.48), and presentation (+0.33), though minimal changes or decreases were noted in significance (-0.05) and contribution (+0.03).
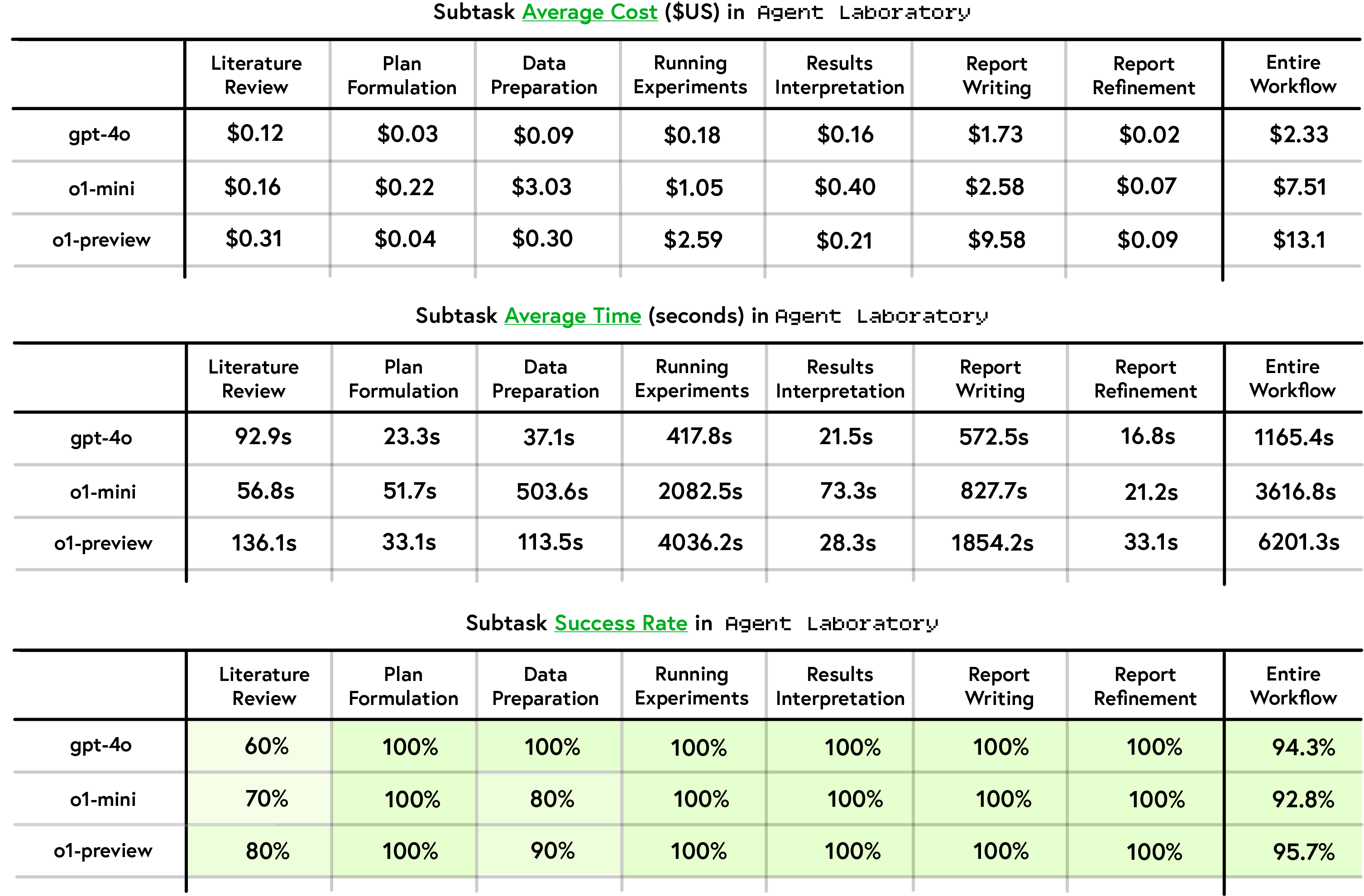
The runtime and cost analysis of Agent Laboratory revealed that gpt-4o was the most computationally efficient and cost-effective model backend, completing the entire workflow in 1165.4 seconds at a cost of $2.33, significantly outperforming o1-mini and o1-preview. o1-mini and o1-preview required 3616.8 and 6201.3 seconds, respectively, with costs of $7.51 and $13.10 per workflow. gpt-4o excelled in speed and cost across key subtasks, including Running Experiments and Report Writing, where it was 3–5x faster and far cheaper than its counterparts. Despite these differences, all models achieved high reliability, with gpt-4o recording a 98.5% success rate and o1-mini and o1-preview achieving 95.7%. Report Writing emerged as the most expensive phase, particularly for o1-preview, which incurred a cost of $9.58 for this task alone.
In this section, I hope to highlight many of the amazing related works being done other groups. The Virtual Lab introduces a team of LLM agents working as scientists alongside a human researcher who provides high-level feedback, with the end result being novel nanobody binders aimed at addressing recent variants of SARS-CoV-2. ChemCrow and Coscientist Coscientist demonstrate the ability for autonomous ideation and experimentation in chemistry. ResearchAgent automates research idea generation, experiment design, and iterative refinement using feedback from reviewing agents aligned with human evaluation criteria. The AI Scientist extends this automation to encompass end-to-end scientific discovery, including coding, experiment execution, and automated peer review for manuscript generation. Despite these advancements, the paper "Can LLMs Generate Novel Research Ideas?" highlight limitations in the feasibility and implementation details of LLM ideation, indicating a complementary rather than replacement role for LLMs in research. We hope to see many more exciting works in autonomous research and hope that Agent Laboratory can help you with your own research!
@misc{schmidgall2025agentlaboratoryusingllm,
title={Agent Laboratory: Using LLM Agents as Research Assistants},
author={Samuel Schmidgall and Yusheng Su and Ze Wang and Ximeng Sun and Jialian Wu and Xiaodong Yu and Jiang Liu and Michael Moor and Zicheng Liu and Emad Barsoum},
year={2025},
eprint={2501.04227},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2501.04227},
}